What you can do with this
- Build customer support agents that answer questions using your help documentation
- Create internal knowledge assistants to help employees find information quickly
- Develop product information bots that provide detailed specs and features
- Design training assistants for interactive learning experiences
- Ensure compliance with accurate information delivery for regulatory requirements
What you get
Knowledge-powered intelligence- Instant expertise: Your Agent immediately knows your content and can answer related questions
- Contextual responses: Provides accurate answers based on your specific information
- Content updates: Automatically stays current as you update your Knowledge Base
- Source citations: Can reference specific documents or sections when answering
- Domain expertise: Specialized knowledge in your specific field or industry
Step-by-step creation process
Click Create from Knowledge card
Navigate to the Create Agent page and click on the Create from Knowledge card to begin the process.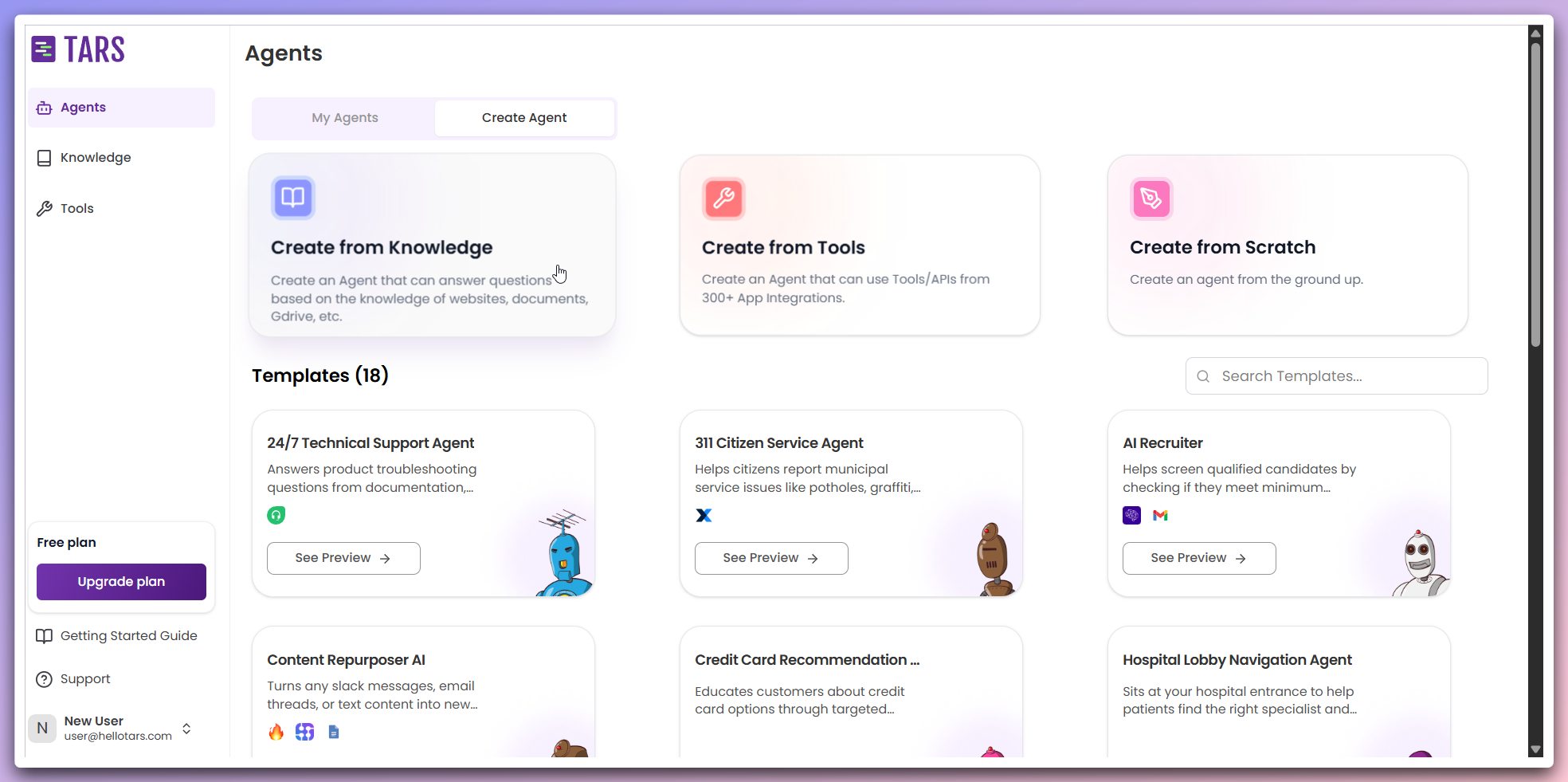
This opens a modal dialog where you can configure your knowledge-powered Agent.
Select Website data source and customize Agent
In the modal, select Website as the data source for training your Agent’s Knowledge Base and customize the Agent’s appearance: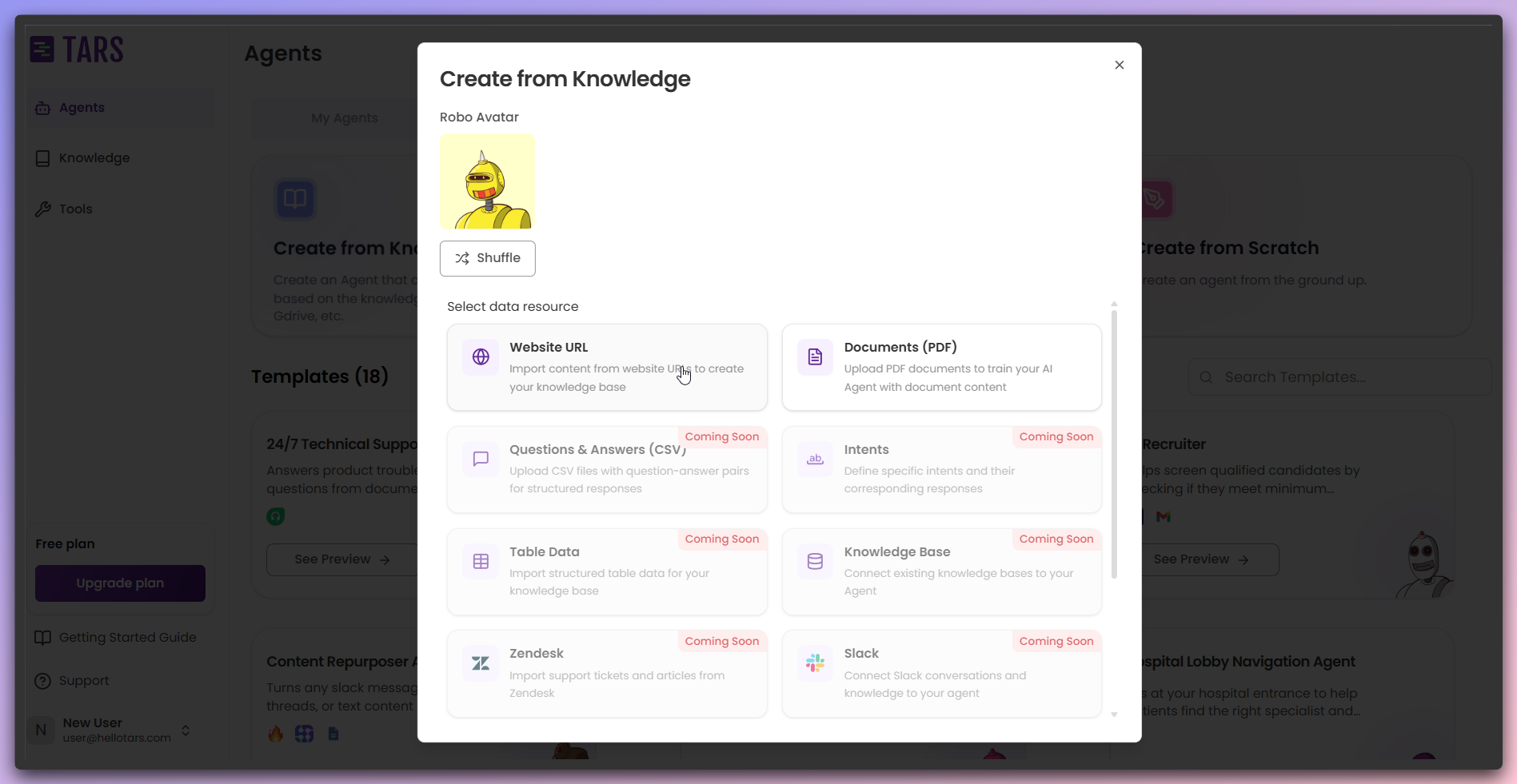
- Data Source: Choose Website to train from web content
- Agent Icon: Select or change the icon representing your Agent
You can choose from various data sources and customize your Agent’s icon. Additional data source options will be introduced in future updates.
Configure Knowledge Base settings
Enter the 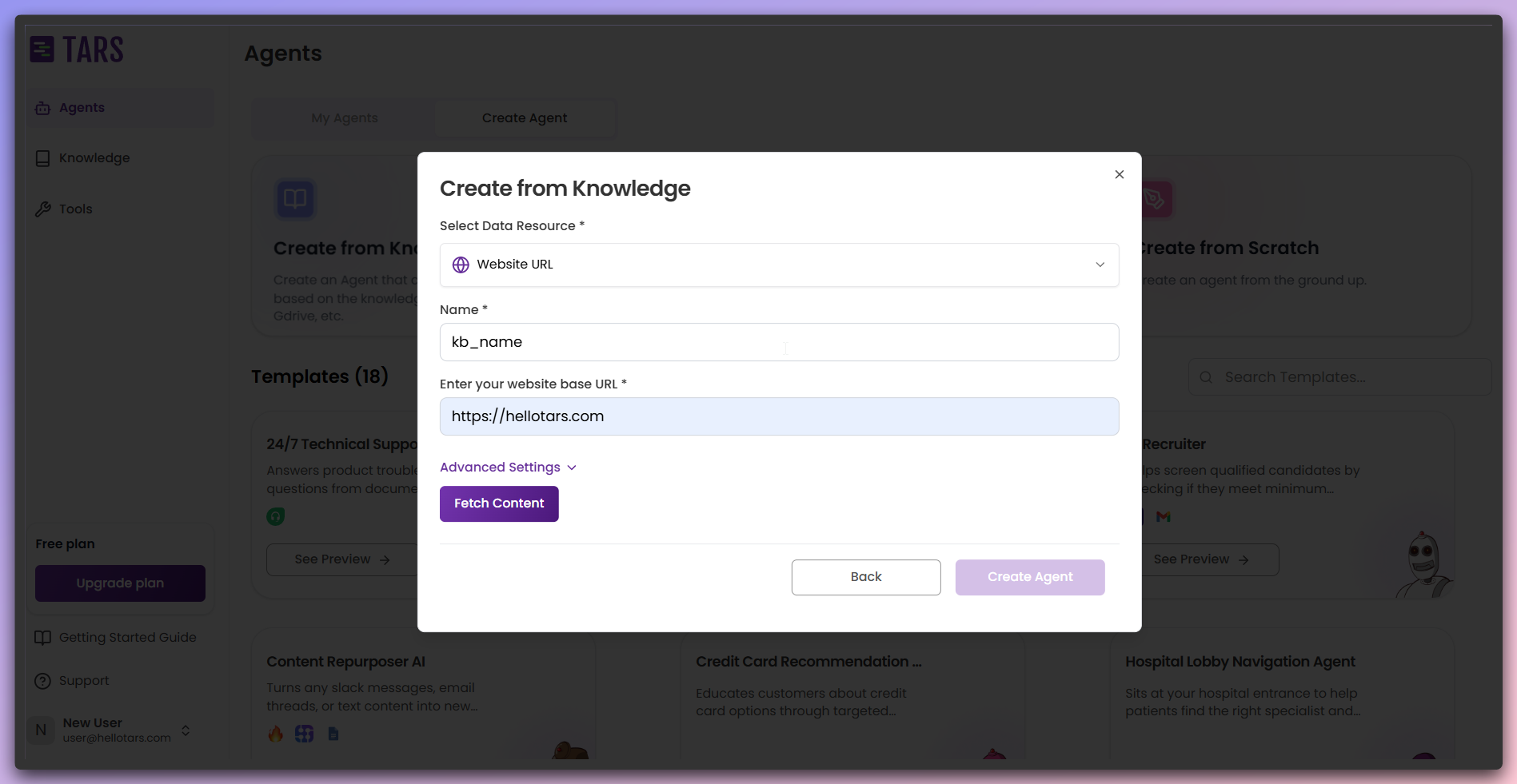
Knowledge Base Name and Website Base URL, then configure
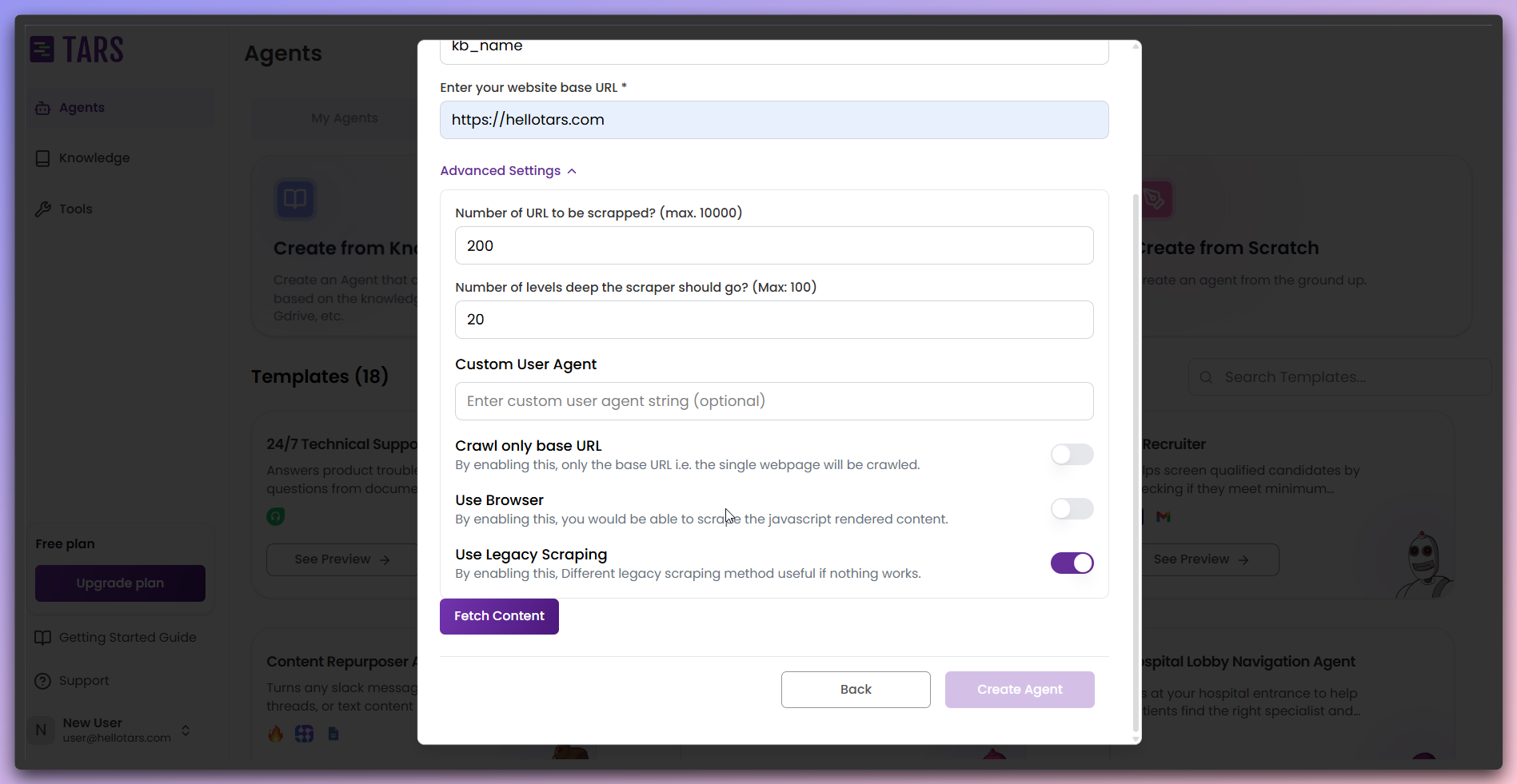
advanced scraping settings if needed.- Basic Configuration
- Advanced Settings
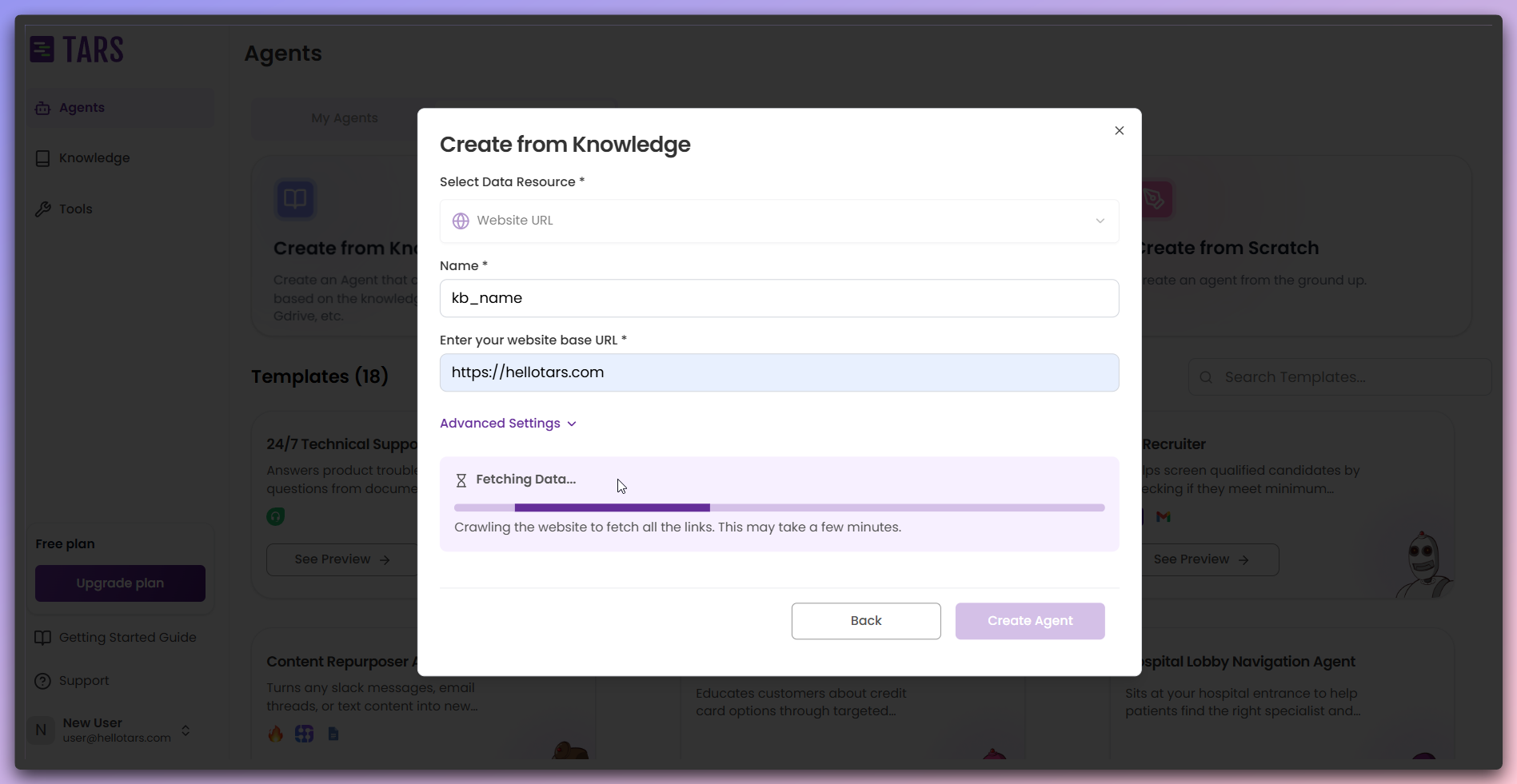
Fetch and process content
Click the 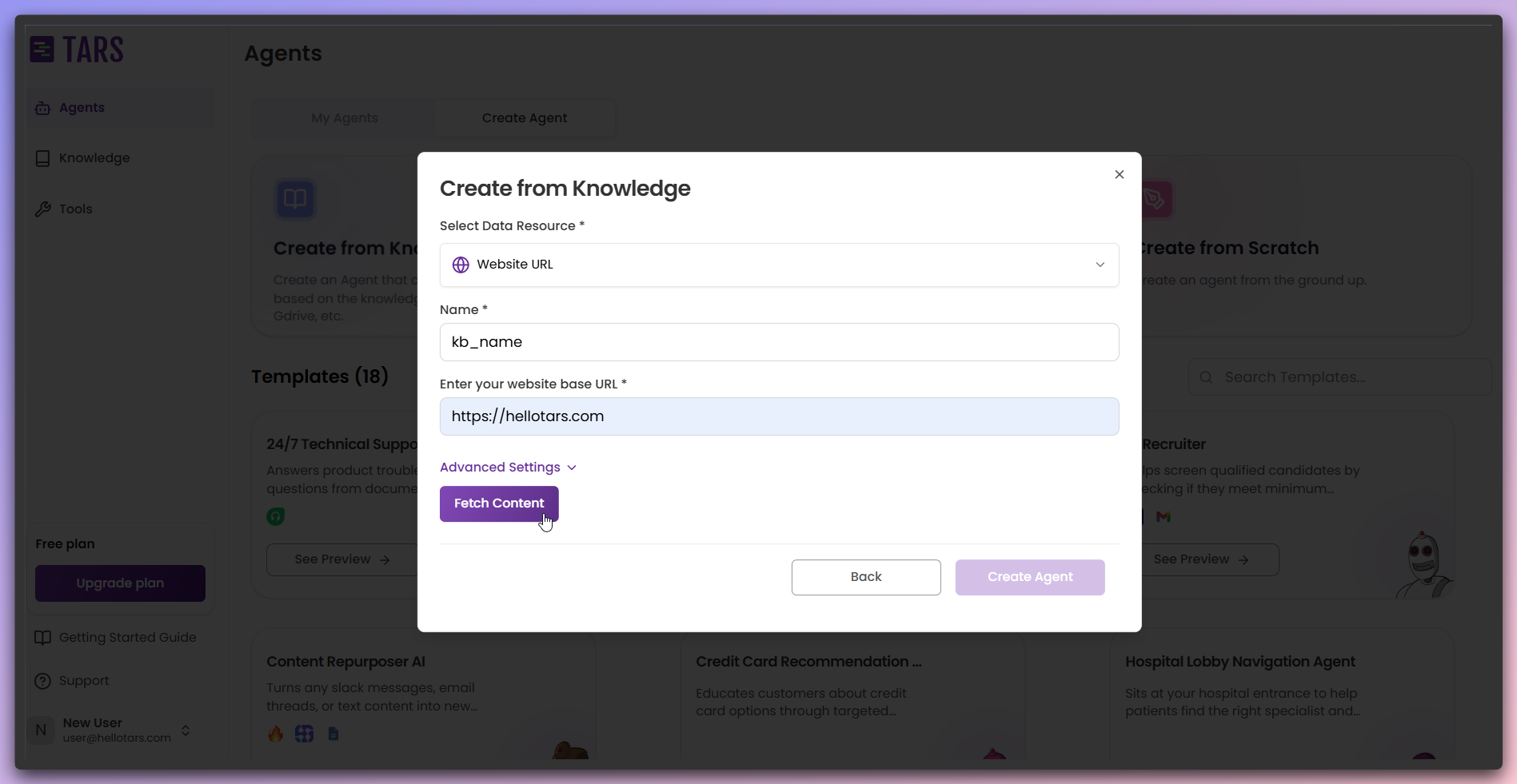
Fetch Links button to begin the web scraping process.- Pre-fetch
- While fetching
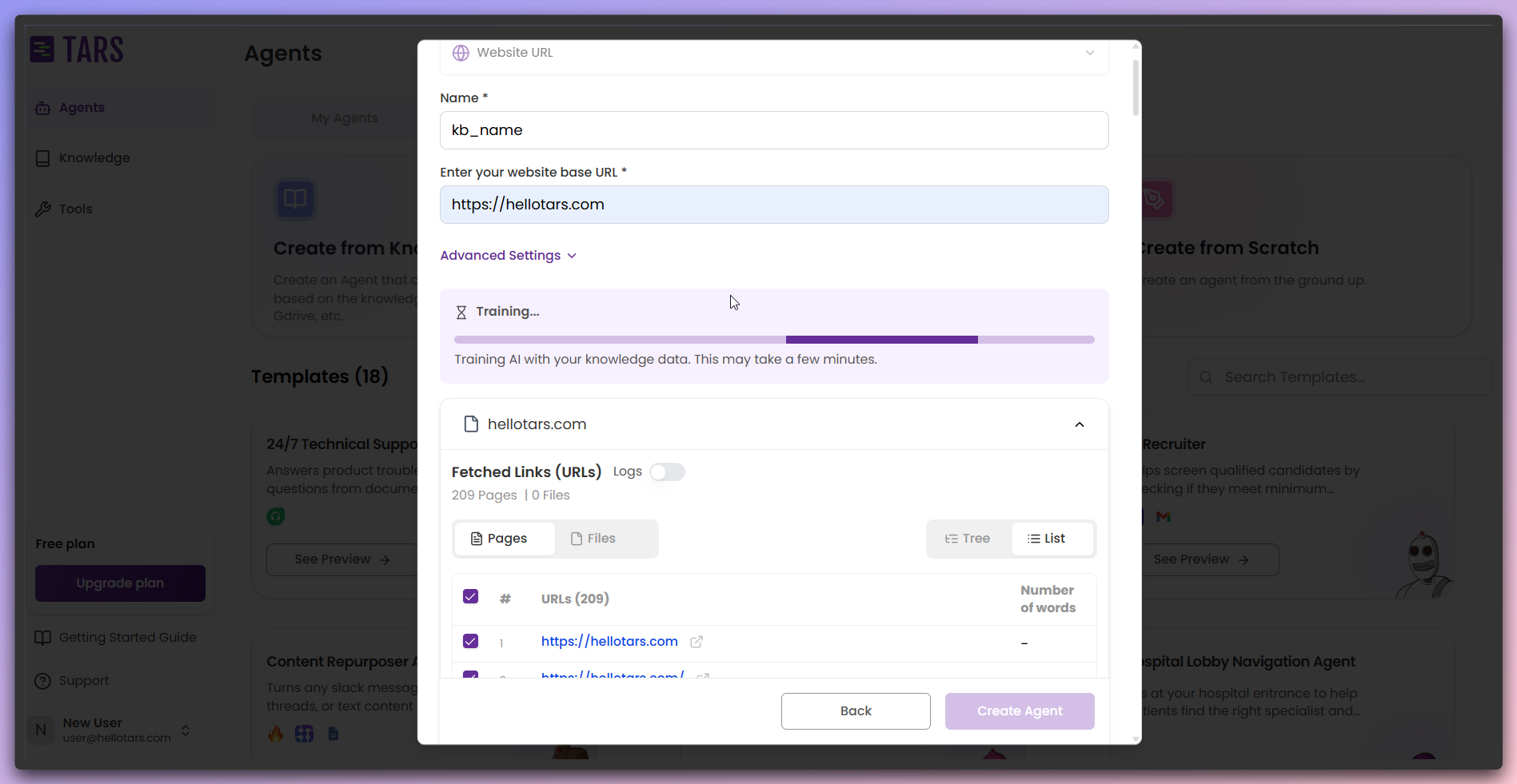
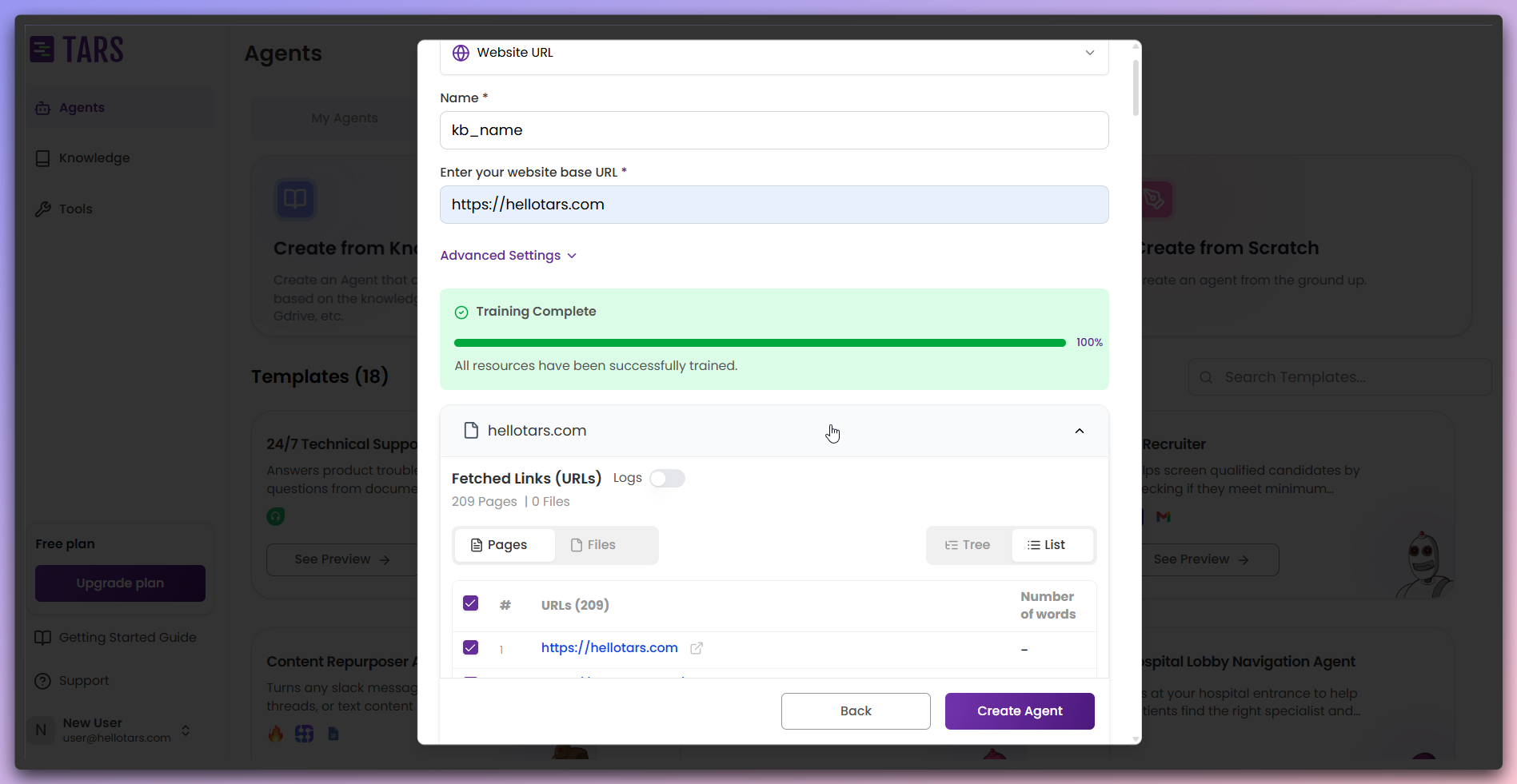
Train the Knowledge Base
After content is successfully fetched, click 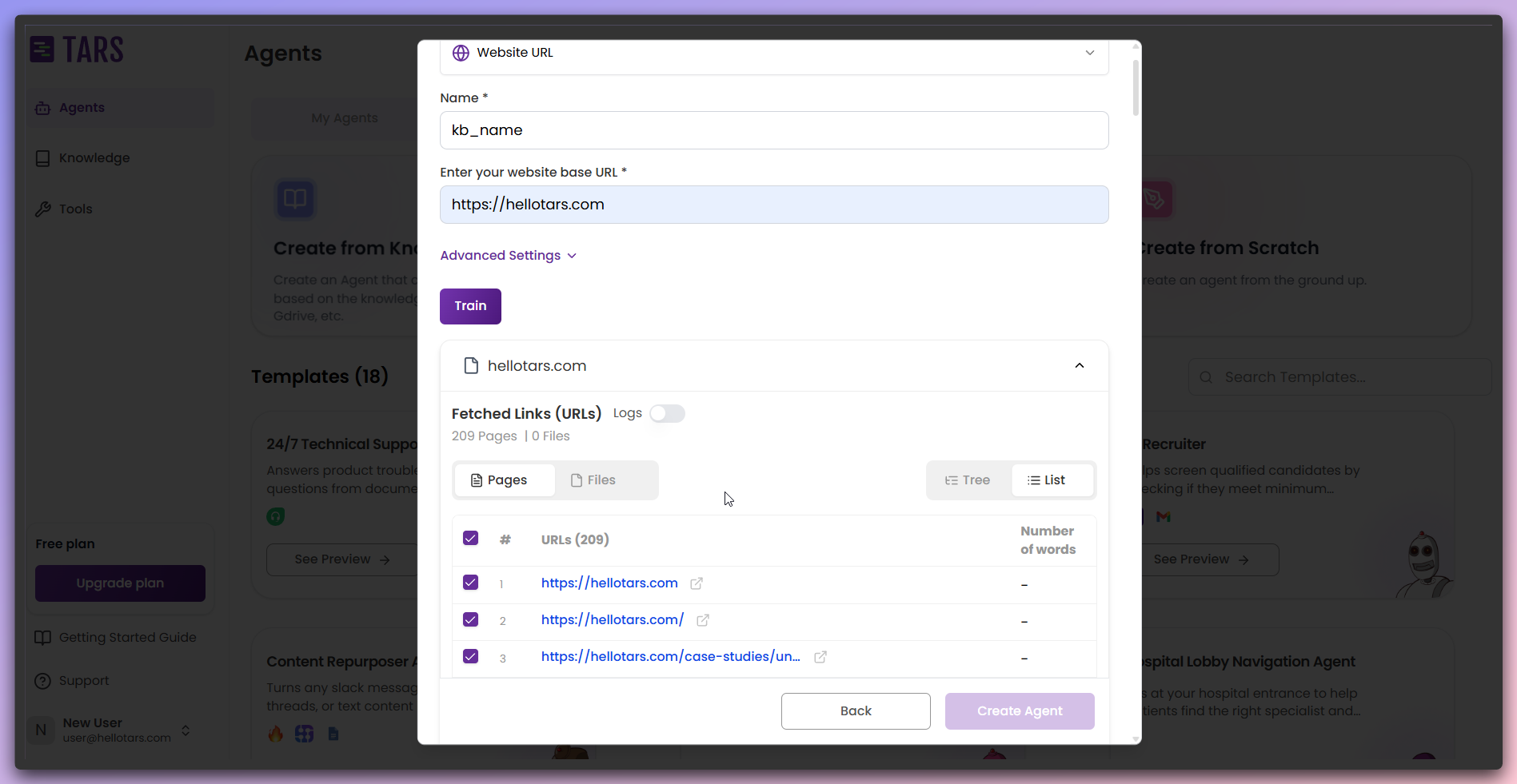
Train to process and train your
Knowledge Base.- Pre-training
- While training
- Post-training